
Via 春潮频道;
正则表达式有什么用?
正则表达式的作用有:1.检测字符串内的模式;2.替换文本;3.基于模式匹配从字符串中提取子字符串。 其中“检测字符串内的模式”作用可以判断从整体字符串中看是否包含指定的字符串,从而判断用户在注册页面输入的内容是否符合验证规则。 Via Net;
正则表达式的应用场景有很多,如代理工具:Surge/Quantumultx/小火箭(如用于匹配节点名符合某些特征的节点,例如节点名含TaiWan且后缀Netflix的节点==;匹配节点名除TaiWan外的所有节点...),JavaScript,Linux的grep/awk/sed ...
利用Surge/QuantumultX 在网页的 head标签 内插入.js/.css文件:
let reg = '<head>';
let replace = '<head><link rel="stylesheet" href="https://limbopro.com/CSS/Adblock4limbo.user.css" type="text/css" /><script type="text/javascript" async="async" src="https://limbopro.com/Adguard/Adblock4limbo.user.js"></script>'
let body = $response.body
.replace(reg, replace)
$done({ body });博主常使用的在线正则表达式工具:https://tool.oschina.net/regex/
我们想要什么
cdn.tsyndicate.com/sdk/v1/master.spot.js如上原始文本所示,是一串网址的集合,其每个网址对应js文件资源所在路径,现在我们只想要匹配(提取)域名部分;一个个选取复制?也不是不行。
本文仅以此举例,以便能以较快的速度入门正则表达式(假设有1w行网址呢?提取域名并进行去重,或计算域名重复次数并进行排序等等)。
域名的结构
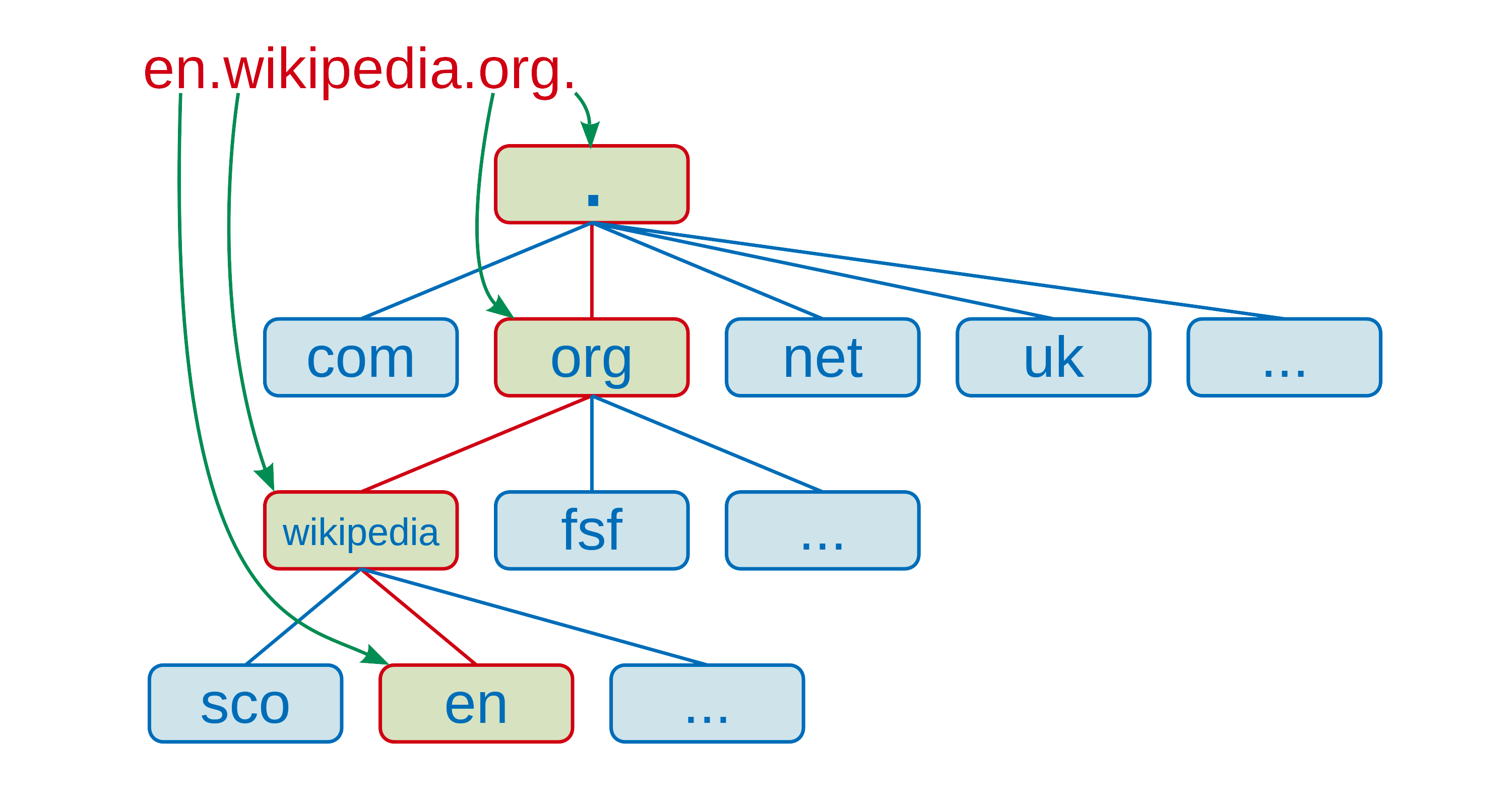
.org
wikipedia.org
en.wikipedia.org
zh.wikipedia.org域名由多个部分组成,这些部分通常连接在一起,并由点分隔,例如zh.wikipedia.org。最右边的一个标签是顶级域名,例如zh.wikipedia.org 的顶级域名是 org。一个域名的层次结构,从右侧到左侧隔一个点依次下降一层。每个标签可以包含1到63个八字节。域名的结尾有时候还有一点,这是保留给根节点的,书写时通常省略,在查询时由软件内部补上。 Via 维基百科;
域名中只能包含以下字符
1.26个英文字母
2."0,1,2,3,4,5,6,7,8,9"十个数字
3."-"(英文中的连词号,但不能是第一个字符或者最后一个字符)
4.对于中文域名而言,还可以含有中文字符而且是必须含有中文字符(日文、韩文等域名类似)。
get?
数字-字母.(com|org|xyz)
数字-字母.数字字母.(com|org|xyz)正则表达式(快速入门)
构造正则表达式的方法和创建数学表达式的方法一样。也就是用多种元字符与运算符可以将小的表达式结合在一起来创建更大的表达式。正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为"元字符")组成的文字模式。模式描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
元字符
| 字符 | 描述 |
|---|---|
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,'n' 匹配字符 "n"。'\n' 匹配一个换行符。序列 '\' 匹配 "\" 而 "(" 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。 |
| * | 匹配前面的子表达式零次或多次。例如,zo 能匹配 "z" 以及 "zoo"。 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 "oooo",'o+?' 将匹配单个 "o",而 'o+' 将匹配所有 'o'。 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用像"(.|\n)"的模式。 |
| (pattern) | 匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 '(' 或 ')'。 |
| (?:pattern) | 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 "或" 字符 (|) 来组合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个比 'industry|industries' 更简略的表达式。 |
| (?=pattern) | 正向肯定预查(look ahead positive assert),在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,"Windows(?=95|98|NT|2000)"能匹配"Windows2000"中的"Windows",但不能匹配"Windows3.1"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如"Windows(?!95|98|NT|2000)"能匹配"Windows3.1"中的"Windows",但不能匹配"Windows2000"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?<=pattern) | 反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反。例如,"(?<=95|98|NT|2000)Windows"能匹配"2000Windows"中的"Windows",但不能匹配"3.1Windows"中的"Windows"。 |
| (?<!pattern) | 反向否定预查,与正向否定预查类似,只是方向相反。例如"(?<!95|98|NT|2000)Windows"能匹配"3.1Windows"中的"Windows",但不能匹配"2000Windows"中的"Windows"。 |
| x|y | 匹配 x 或 y。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'、'l'、'i'、'n'。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,'[a-z]' 可以匹配 'a' 到 'z' 范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,'[^a-z]' 可以匹配任何不在 'a' 到 'z' 范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \cx | 匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
| \w | 匹配字母、数字、下划线。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配非字母、数字、下划线。等价于 '[^A-Za-z0-9_]'。 |
| \xn | 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,'\x41' 匹配 "A"。'\x041' 则等价于 '\x04' & "1"。正则表达式中可以使用 ASCII 编码。 |
| \num | 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,'(.)\1' 匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 |
| \nml | 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。 |
| \un | 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。 |
定位符
定位符使您能够将正则表达式固定到行首或行尾。它们还使您能够创建这样的正则表达式,这些正则表达式出现在一个单词内、在一个单词的开头或者一个单词的结尾。
定位符用来描述字符串或单词的边界,^ 和 $ 分别指字符串的开始与结束,\b 描述单词的前或后边界,\B 表示非单词边界。
正则表达式的定位符有:
| 字符 | 描述 |
|---|---|
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 |
| \b | 匹配一个单词边界,即字与空格间的位置。 |
| \B | 非单词边界匹配。 |
限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 *** 或 + 或 ? 或 {n} 或 {n,} 或 {n,m}** 共6种。
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。*** 等价于 {0,}**。 |
| + | 匹配前面的子表达式一次或多次。例如,zo+ 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,do(es)? 可以匹配 "do" 、 "does"、 "doxy" 中的 "do" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,o{2} 不能匹配 "Bob" 中的 o,但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,o{2,} 不能匹配 "Bob" 中的 o,但能匹配 "foooood" 中的所有 o。o{1,} 等价于 o+。o{0,} 则等价于 o*。 |
| {n,m} | m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,o{1,3} 将匹配 "fooooood" 中的前三个 o。o{0,1} 等价于 o?。请注意在逗号和两个数之间不能有空格。 |
特别字符
正则表达式的特别字符有:
| 特别字符 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。要匹配 $ 字符本身,请使用 \$。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 ( 和 )。 |
| * | 匹配前面的子表达式零次或多次。要匹配 字符,请使用 \。 |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 +。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 . 。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 [。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\' 匹配 "\",而 '(' 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配 ^ 字符本身,请使用 \^。 |
| { | 标记限定符表达式的开始。要匹配 {,请使用 {。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 |。 |
正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常类似。
Via 正则表达式语法;
原始文本(示例)
原始文本:
cdn.tsyndicate.com/sdk/v1/master.spot.js
creative.live.missav.com/widgets/Spot/lib.js
clurd09pla4nrtat7ion.com/lv/esnk/1889931/code.js
e67repidwnfu7gcha.com/lv/esnk/1924088/code.js
clurd09pla4nrtat7ion.com/lv/esnk/1889930/code.js
e67repidwnfu7gcha.com/lv/esnk/1924089/code.js
wuzbhjpvsf.com/lv/esnk/1939281/code.js
cdn.tsyndicate.com/sdk/v1/inpage.push.js写正则表达式
现在我们要提取他们的域名部分;
这里根据域名的特征,使用的正则表达式如下(不够严谨,但足够):
(\w{2,20}\.){1,3}\w{2,4}(?=\/)博主常使用的在线正则表达式工具:https://tool.oschina.net/regex/ ,打开,复制示例文本,自行尝试写正则表达式进行匹配;
匹配结果:
共找到 8 处匹配:
cdn.tsyndicate.com
creative.live.missav.com
clurd09pla4nrtat7ion.com
e67repidwnfu7gcha.com
clurd09pla4nrtat7ion.com
e67repidwnfu7gcha.com
wuzbhjpvsf.com
cdn.tsyndicate.com解释
| 字符 | 描述 |
|---|---|
| \w | 匹配字母、数字、下划线。等价于'[A-Za-z0-9_]'。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
| * | 匹配前面的子表达式零次或多次。例如,zo 能匹配 "z" 以及 "zoo"。 等价于{0,}。 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用像"(.|\n)"的模式。 |
| ? | 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 "oooo",'o+?' 将匹配单个 "o",而 'o+' 将匹配所有 'o'。 |
| (?=pattern) | 正向肯定预查(look ahead positive assert),在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,"Windows(?=95|98|NT|2000)"能匹配"Windows2000"中的"Windows",但不能匹配"Windows3.1"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
匹配与替换(运用)
正则表达式,我们使用括号进行分组;
((\w{2,20}\.){1,3}\w{2,4}.*?\.js)()匹配结果
cdn.tsyndicate.com/sdk/v1/master.spot.js
creative.live.missav.com/widgets/Spot/lib.js
clurd09pla4nrtat7ion.com/lv/esnk/1889931/code.js
e67repidwnfu7gcha.com/lv/esnk/1924088/code.js
clurd09pla4nrtat7ion.com/lv/esnk/1889930/code.js
e67repidwnfu7gcha.com/lv/esnk/1924089/code.js
wuzbhjpvsf.com/lv/esnk/1939281/code.js
cdn.tsyndicate.com/sdk/v1/inpage.push.js替换表达式
$1 - reject替换结果
cdn.tsyndicate.com/sdk/v1/master.spot.js - reject
creative.live.missav.com/widgets/Spot/lib.js - reject
clurd09pla4nrtat7ion.com/lv/esnk/1889931/code.js - reject
e67repidwnfu7gcha.com/lv/esnk/1924088/code.js - reject
clurd09pla4nrtat7ion.com/lv/esnk/1889930/code.js - reject
e67repidwnfu7gcha.com/lv/esnk/1924089/code.js - reject
wuzbhjpvsf.com/lv/esnk/1939281/code.js - reject
cdn.tsyndicate.com/sdk/v1/inpage.push.js - reject如果你是 Surge/QuantumultX 用户(爱折腾去广告),大概知道为什么要进行这些操作。
Ok,以上。
代码(文本)编辑器
Visual Studio Code
NOTEPAD++
VIM
ATOM
版权属于:毒奶
联系我们:https://limbopro.com/6.html
毒奶搜索:https://limbopro.com/search.html
番号搜索:https://limbopro.com/btsearch.html
机场推荐:https://limbopro.com/865.html IEPL专线/100Gb/¥15/月起(最高享8折优惠)
毒奶导航:https://limbopro.com/daohang/index.html本文链接:https://limbopro.com/archives/24076.html · 镜像:https://limbopro.github.io/archives/24076.html
本文采用 CC BY-NC-SA 4.0 许可协议,转载或引用本文时请遵守许可协议,注明出处、不得用于商业用途!




