
Via civitai;
AIGC 是什么
AIGC 又称生成式 AI (Generative AI),是继专业生产内容(PGC, Professional-generated Content)、用户生产内容(UGC, User-generated Content)之后的新型内容创作方式,可以在对话、故事、图像、视频和音乐制作等方面,打造新的数字内容生成与交互形式。
与所有人工智能技术一样,AIGC 的能力由机器学习模型提供,这些模型是基于大量数据进行预先训练的大模型,通常被称为基础模型(Foundation Models)。如今以基础模型为驱动的 AIGC 应用迭代速度呈现指数级发展,从由 Stable Diffusion 文生图模型驱动的 AI 作画应用,再到以大语言模型(LLM)驱动的智能聊天机器人,深度学习模型不断完善、开源预训练基础模型的推动以及大模型探索商业化的可能,都在成为这场人工智能颠覆性革命的主要驱动力。
应用
图像生成(Stable Diffusion/midJourney..)
文本生成(ChatGPT/Google Bard..)
视频生成(CapCut/Runway..)
多模态生成(复合类型)Stable Diffusion 介绍
Stable Diffusion是2022年发布的深度学习文字到图像生成模型。它主要用于根据文字的描述产生详细图像,修复(向现有图像添加特征)、修复(从现有图像中删除特征)以及在文本提示的引导下生成图像到图像的转换;尽管它也可以应用于其他任务,如内补绘制、外补绘制,以及在提示词指导下产生图生图的翻译。
它是一种潜在变量模型的扩散模型,由慕尼黑大学的CompVis研究团体开发的各种生成性类神经网络。它是由初创公司StabilityAI、CompVis与Runway合作开发,并得到EleutherAI和LAION(英语)的支持。 截至2022年10月,StabilityAI筹集了1.01亿美元的资金。
Stable Diffusion 入门指南
从安装到入门,仅需3个步骤;
stable-diffusion-webui 介绍/Python/依赖安装
stable-diffusion-webui 扩展推荐/中文扩展
常用网站/模型下载/优化提示词...
Stable-diffusion-webui 介绍(安装)
A browser interface based on Gradio library for Stable Diffusion. 用于 Stable Diffusion 浏览器界面(webui),基于 Gradio 库打造。(大家不要拿去生成NSFW啊!)
系统要求
GPU/CPU:配置越高越好,对出图速度很有帮助;
浏览器:推荐基于 Chromium 内核开发的浏览器,如 Chrome;
stable-diffusion-webui 仓库地址:https://github.com/AUTOMATIC1111/stable-diffusion-webui (本文均以macOS 举例,Windows/Linux 用户可完全参阅项目的 readme ,对于 Windows用户来讲,双击双击再双击就可以搞定了;很方便;)
Python 版本要求: Python 3.10.6;
Git:需安装Git,下载安装;
模型下载:推荐C站;https://civitai.com/ 或参考本文 模型下载部分;
安装 Python 3.10.6
1.点击 Python 3.10.6 进入下载页面;以 macOS 举例 -> 滑至页面底部 -> Files -> 点击下载 macOS 64-bit universal2 installer;
2.下载完成后双击安装即可;
安装 Git(及克隆项目)
1.点击进入下载页面;以 macOS 举例 -> 透过 Homebrew 安装(如果没安装 Homebrew,点此下载安装 Homebrew):
$ brew install git下载 stable-diffusion-webui 源码到本地
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git懒得安装 Git? 那就直接打包下载! https://github.com/AUTOMATIC1111/stable-diffusion-webui/archive/refs/heads/master.zip 或 https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.4.0 下载 Source Code;自行解压,并修改解压后的文件夹名称为 stable-diffusion-webui(stable-diffusion-webui-master);
运行 stable-diffusion-webui
以 macOS /Linux 为例:下载完成后进入文件目录(举例),打开终端 App - >
$ cd /Users/xxx/stable-diffusion-webui/(请以自己的路径为准)
$ ./webui.sh浏览器访问:http://127.0.0.1:7860/ (默认);
Windows 运行 webui-user.bat 文件:
webui-user.bat如何更快运行 stable-diffusion-webui
制作一个名为stable diffusion.sh 的脚本文件(以.sh为后缀!),放置在 应用程序 文件夹下;
#! /bin/bash
cd "/Users/xxx/stable-diffusion-webui" (请你的路径为准)
./webui.shOK,保存;
每次想打开的时候:快捷键 command + 空格键,输入 stable ... 然后就会出来了,选中打开即可;
安装中文界面扩展
本 webUI 默认为英文显示,可通过安装中文扩展包以支持中文显示;(更多好玩扩展推荐可查阅本文 学习资料 部分);
博主使用的是 VinsonLaro 提供的 stable-diffusion-webui-chinese;点此查看安装说明:GitHub - VinsonLaro/stable-diffusion-webui-chinese: stable-diffusion-webui 的汉化版本;
推荐大家使用支持中英文双语显示的sd-webui-bilingual-localization的;这样后期在网上学习,乃至参考外网英文资料也可以快速找到模块对应;本文使用的部分截图均为中文,在其文字说明部分对各个术语均有双语化;在此不再赘述;
目录结构(模型及扩展安装)
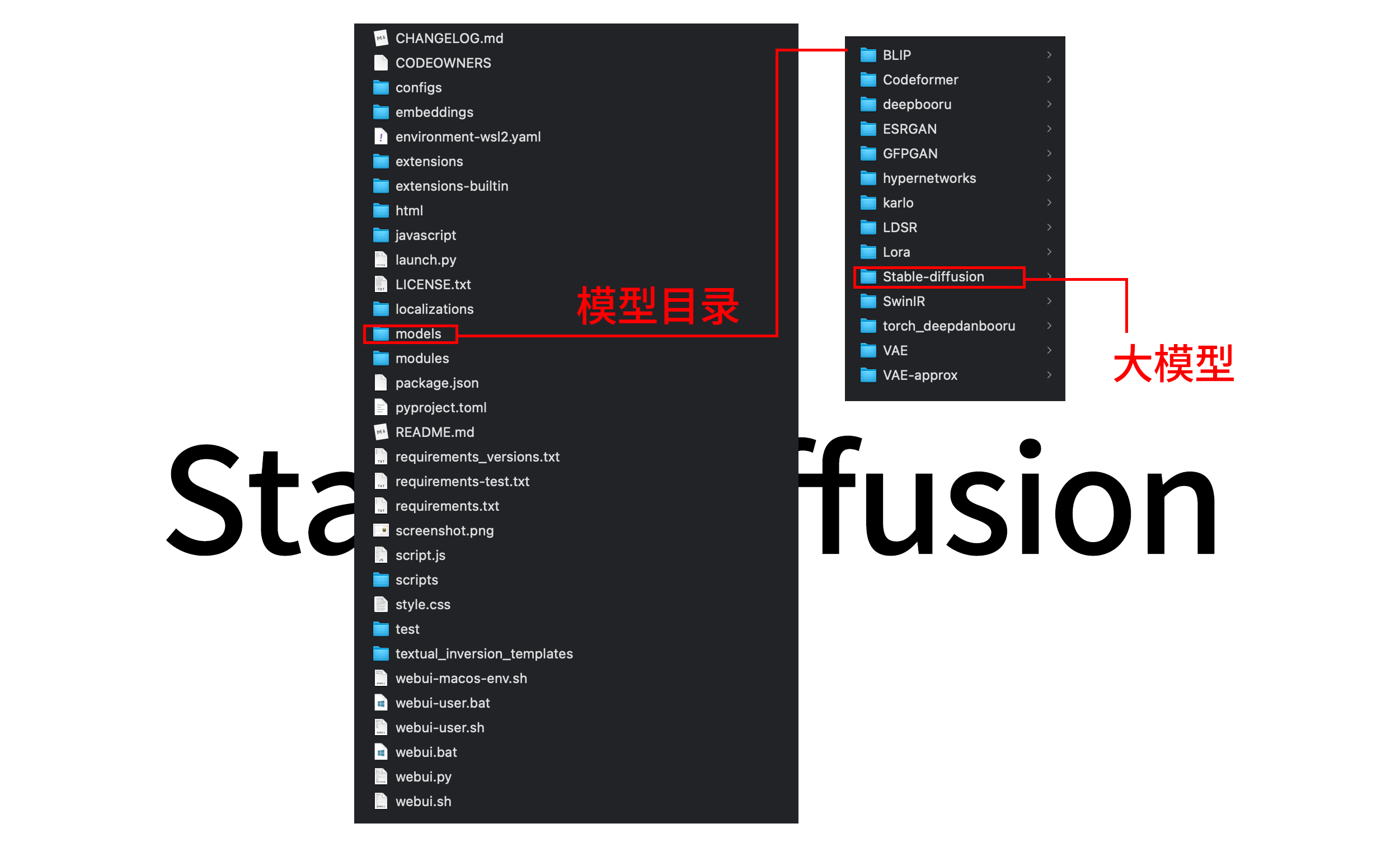
解压后我们可以看到,如上图;stable-diffusion-webui/models 文件夹下,各类型模型放在指定文件夹下,以确保你可以在提示词中调用它们;
BLIP
Lora
deepbooru
Codeformer
Stable-diffusion
hypernetworks
ESRGAN
SwinIR
karlo
GFPGAN
VAE
torch_deepdanbooru
LDSR
VAE-approxmodels/Stable-diffusion 文件夹下的是基础模型,对应类型名称Checkpoints,又称大模型(你可以在 http://127.0.0.1:7860/ 页面左上角选择大模型);
models/Lora 文件夹选的是微调模型;(可以在提示词中调用)
models/VAE 文件夹下放的是美化模型;(可以在提示词中调用)
进一步了解:https://zhuanlan.zhihu.com/p/622410028
提示词调用LoRA模型示例:我们把 deliberate_v2.safetensors 放在 models/Lora 文件夹下;
Ultra-realistic 8k CG,masterpiece,best quality,(photorealistic:1.4),absurdres,HDR,RAW photo,(film grain:1.1),Bokeh,((Depth of field)),raytracing,detailed shadows,dim light,1 girl,full body,((looking at viewer:1.2)),(suspension:1.5),(spread legs:1.2),(shibari:1.4),sexy,(rope:1.3),bound hands,(arms behind back:1.2),(naughty_face:1.3),shaking,struggling,( half naked :1.4),small clothes,(single ponytail:1.3),(blushing face:1.2),((nsfw:1.4)),
(nude:1.2),(dim-lit room :1.2),wooden interior,metal chains,(ropeburns on wrists:1.3),( bra showing:1.3),curvy body,hanging planters,minimal furnishings,<lora:deliberate_v2:0.4>,(from above:1.2)提示词中 <lora:deliberate_v2:0.4> 代表调用 models/lora(文件夹) 下的 deliberate_v2 模型,权重 0.4;意味着,部分画画工作由该模型负责;
LoRA/Checkpoints/Hypernetworks模型调用方法
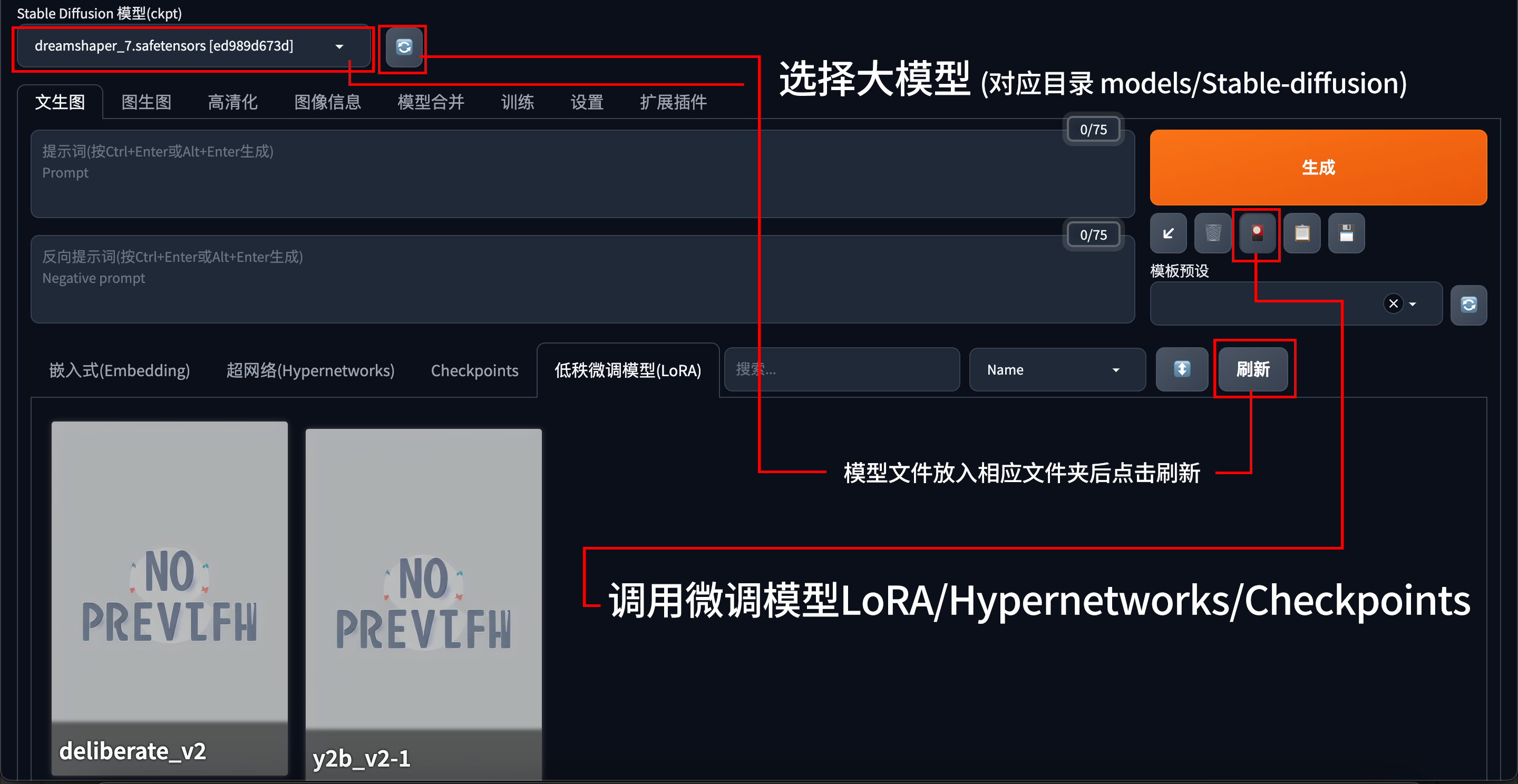
模型介绍/模型哪里下载(经常需要用的)
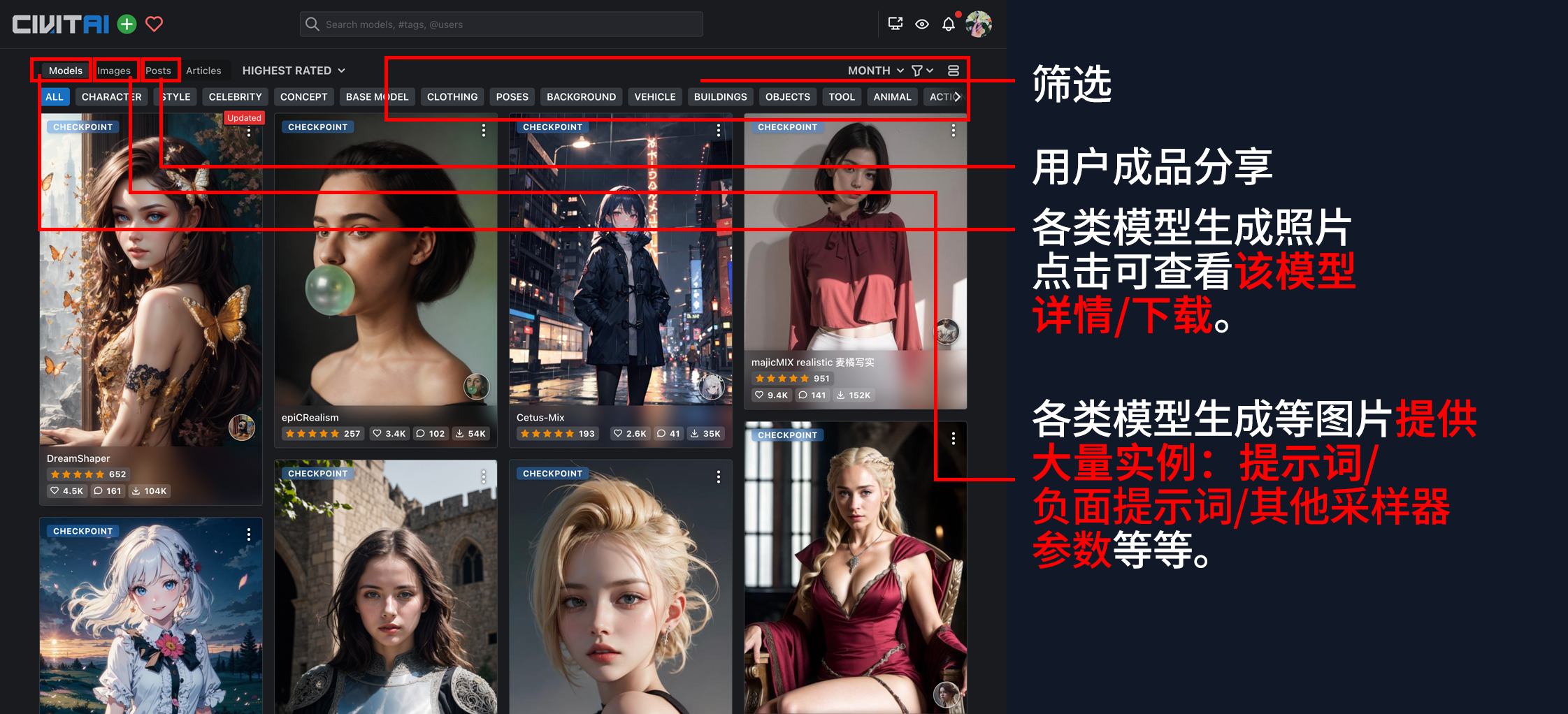
C站首页:https://civitai.com/ 需魔法上网;模型一般百兆到10GB之间,快速的梯子则变得很重要,如没有可参阅文章挑选;
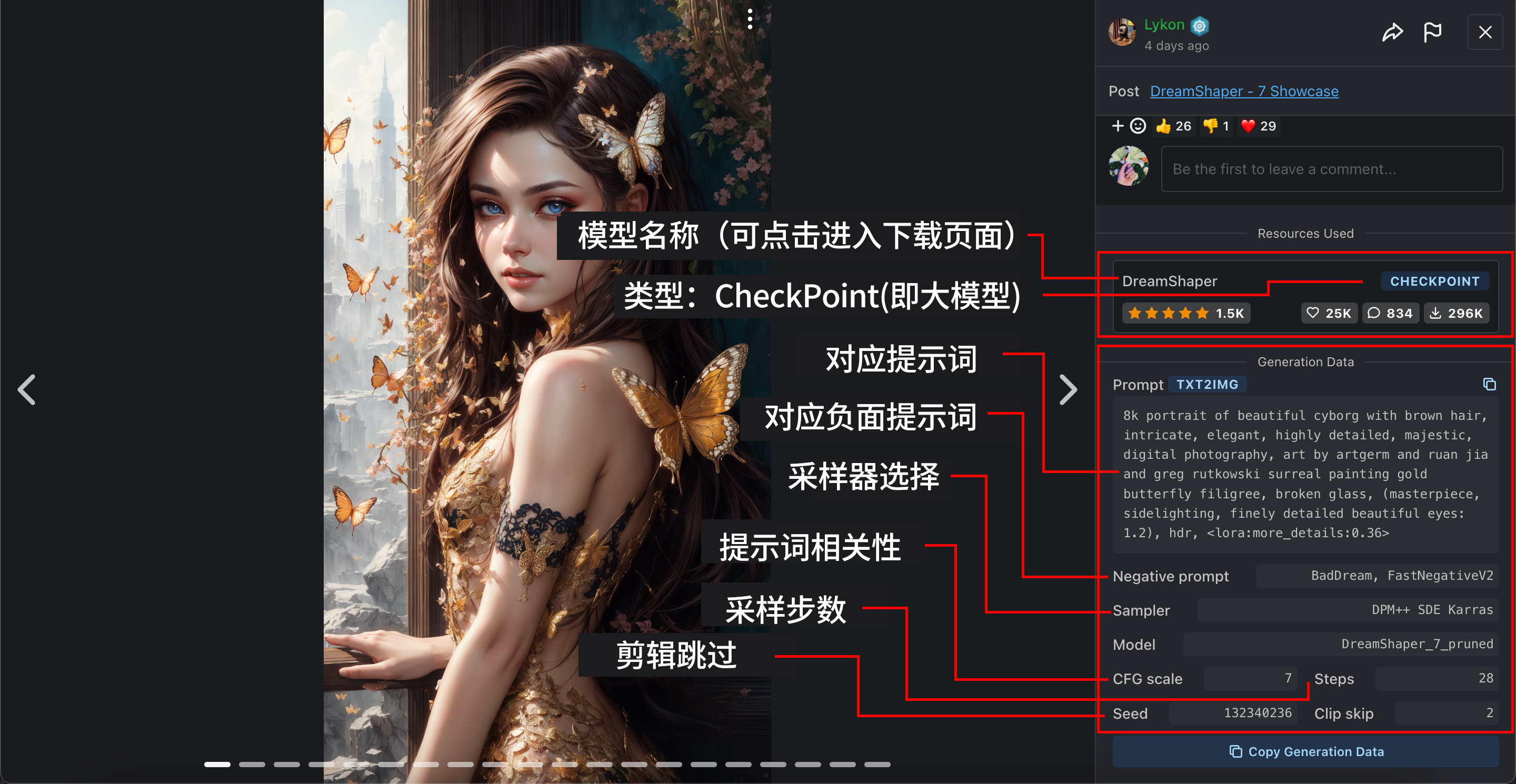
如上图;civitai 使用说明配图来源;
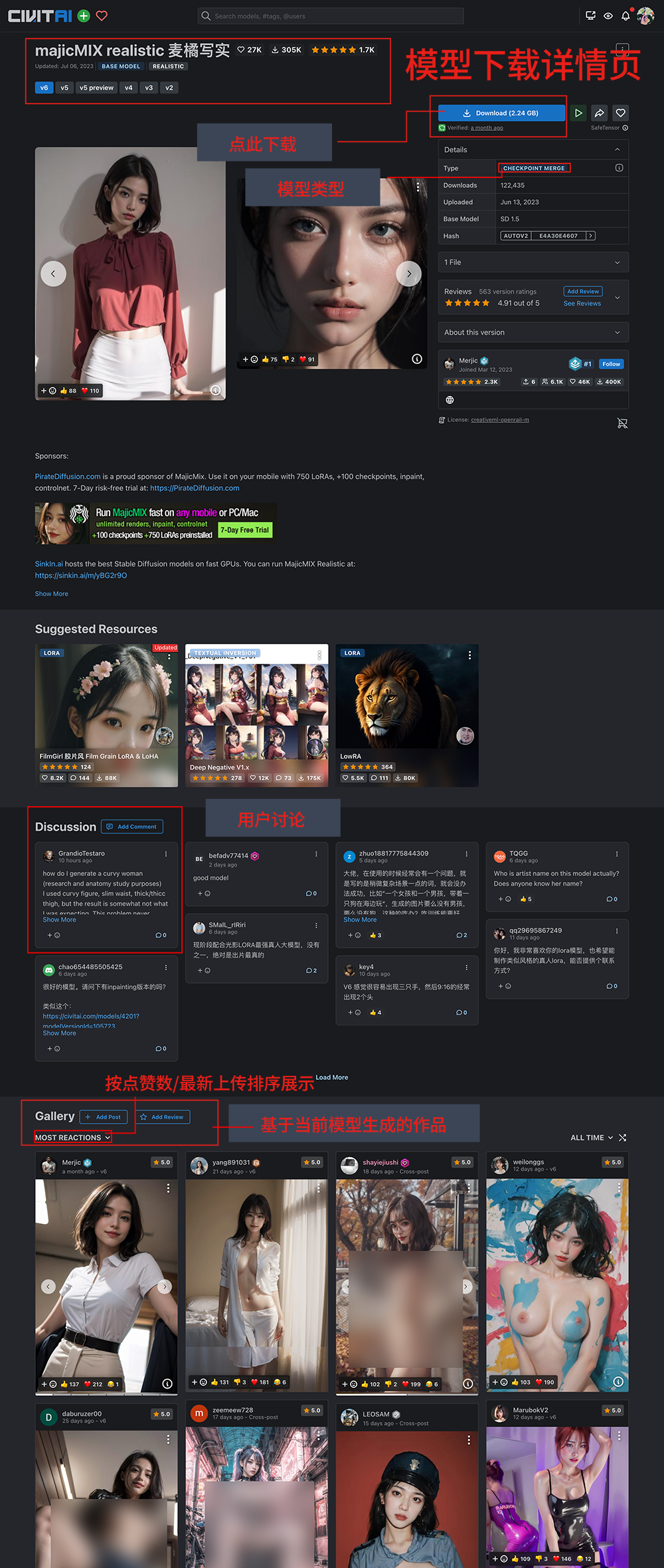
如上图:模型下载详情页来源 majicmix-realistic;毕竟普通用户的机子算力极其有限,所以提前下载他人训练好的模型(可用性程度高)则十分有必要;
官方:v1-5-pruned-emaonly.safetensors · runwayml/stable-diffusion-v1-5 at main -> This file is stored with Git LFS . It is too big to display, but you can still download it.
其他模型:可在C站 https://civitai.com/ 查找想要的模型,并下载;
其他下载方法:以 lora:TotemPunkAI举例:谷歌搜索模型类型即其名字 lora:TotemPunkAI;(我们在C站可以看到很多提示词,生成的图片非常棒,其中提示词中包含的模型在我们没有的情况下可以通过本方法下载;)
偏向真人的
偏向二次元的
偏向拍立得风的
偏向古风的
偏向水墨画的
偏向赛博朋克的
...
很多模型
可以混合使用
完成你的绘图需求CivitAI 上的模型主要分为四类:Checkpoint、LoRA、Textual Inversion、Hypernetwork,分别对应 4 种不同的训练方式。
Checkpoint:通过 Dreambooth 训练方式得到的大模型, 特点是出图效果好,但由于训练的是一个完整的新模型,所以训练速度普遍较慢,生成模型文件较大,一般几个 G,文件格式为 safetensors 或 ckpt。
LoRA:一种轻量化的模型微调训练方法,是在原有大模型的基础上,对该模型进行微调,用于输出固定特征的人或事物。特点是对于特定风格特征的出图效果好,训练速度快,模型文件小,一般几十到一百多 MB,需要搭配大模型使用。
Textual Inversion:一种使用文本提示来训练模型的方法,可以简单理解为一组打包的提示词,用于生成固定特征的人或事物。特点是对于特定风格特征的出图效果好,模型文件非常小,一般几十 K,但是训练速度较慢,需要搭配大模型使用。
Hypernetwork:类似 LoRA,但模型效果不如 LoRA,需要搭配大模型使用。
通常情况 Checkpoint 模型搭配 LoRA 或 Textual Inversion 模型使用,可以获得更好的出图效果。 Via 出图效率倍增!47个高质量的 Stable Diffusion 常用模型推荐;
下载完成后将文件移至 stable-diffusion-webui/models/ 相应文件夹下;(如何应用可参阅本文目录结构部分);
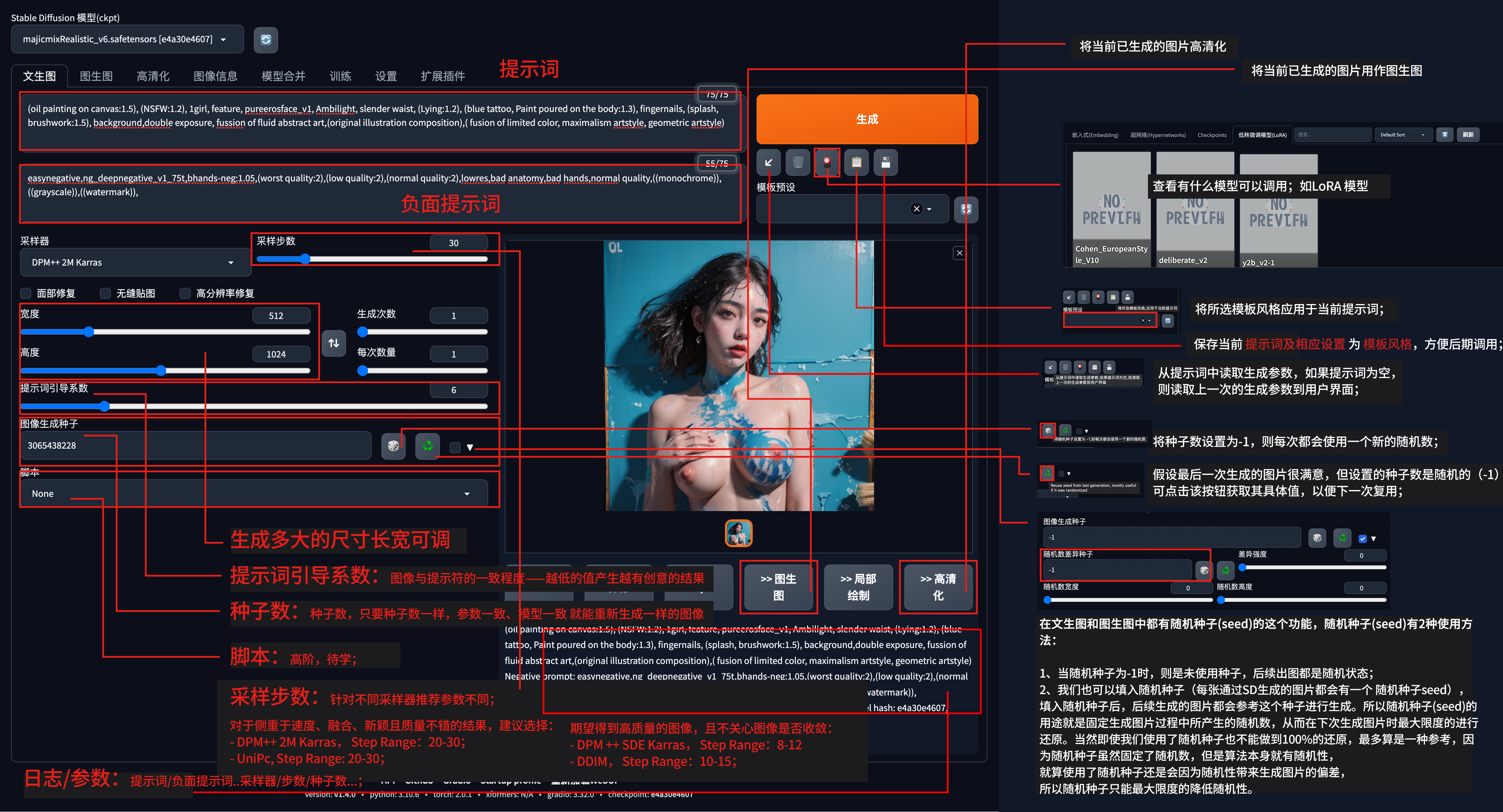
TXT2IMG 文本生成图片(特技1)
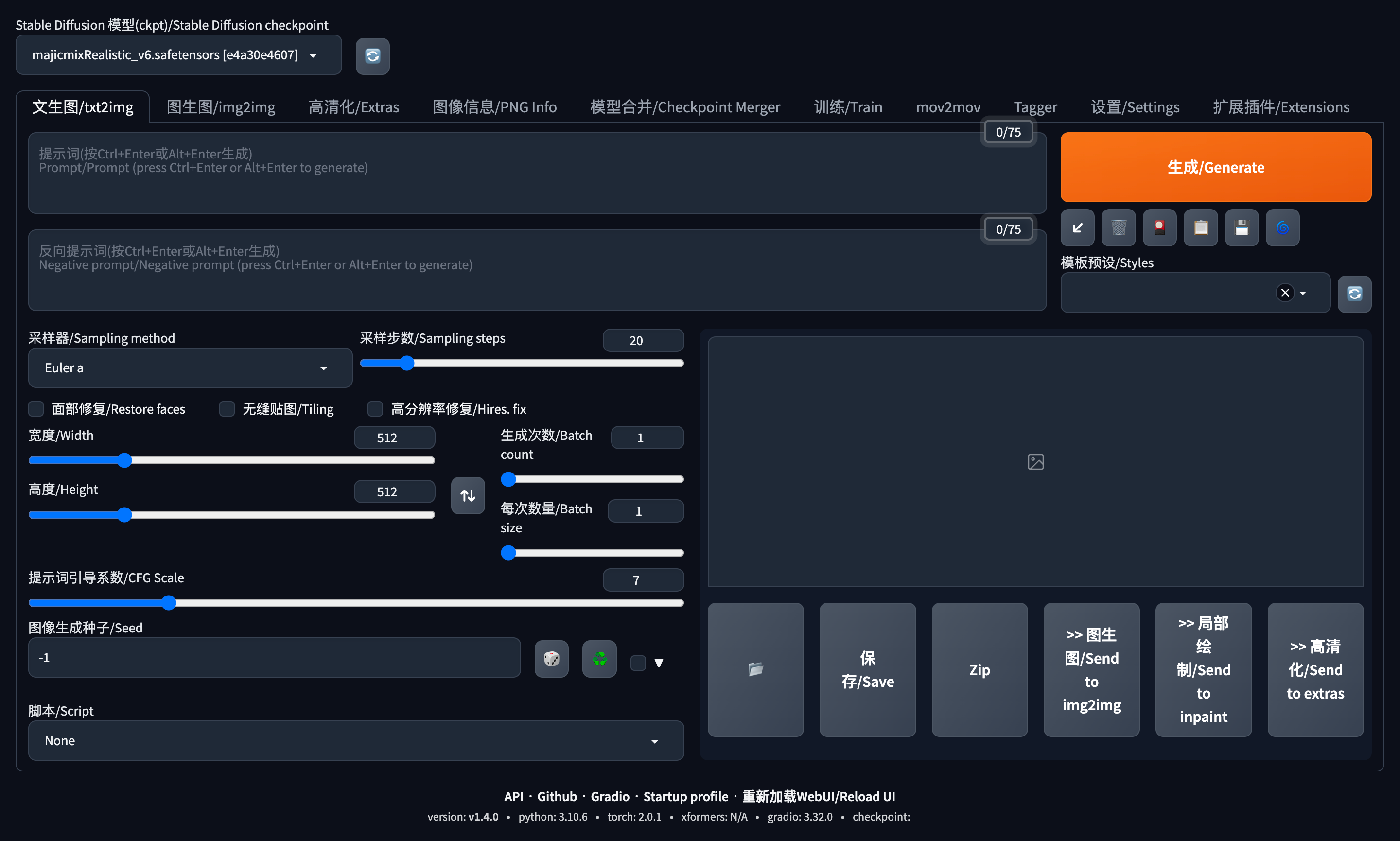
高度/宽度:如果感觉生成的图片不完全则可适当增加宽度或高度(譬如腿部只露出到膝盖..);
提示词引导系数(CFG scale):图像与提示符的一致程度——越低的值产生越有创意的结果;
图像生成种子(seed):种子数,只要种子数一样,参数一致、模型一致 就能重新生成一样的图像;也就说,在其他条件不变的情况下,修改下种子数可以得到更多意想不到的变体(当然,画面主体不变,但有更多演化);种子数为-1时,则代表随机;
随机数差异种子(Variation seed)/差异程度(Variation strength):保持其他条件不变的情况下,调整随机数差异种子或差异强度,可在当前已生成图片的基础上微调;
生成次数(Batch count)/每次生成数量(Batch size):决定生成的图片数量。如果显存足够,则可以增加 Batch Size;否则,只能增加 Batch Count,得到的图片数量是两者之积(对于显存较小的情况,建议只修改 Batch Count)。
采样步数/Sampling steps:不同采样器有不同的采样步数推荐;(关于更多采样步数的说明,请参阅后文 学习资料 部分)
1.如果只是想得到一些较为简单的结果,选用欧拉(Eular)或者Heun,并可适当减少Heun的步骤数以减少时间;
2.对于侧重于速度、融合、新颖且质量不错的结果,建议选择:
- DPM++ 2M Karras, Step Range:20-30
- UniPc, Step Range:20-30
3.期望得到高质量的图像,且不关心图像是否收敛:
- DPM ++ SDE Karras,Step Range:8-12
- DDIM, Step Range:10-15
4.如果期望得到稳定、可重现的图像,避免采用任何祖先采样器;
以C站 civitai 资源为例;说到提示词(需英文书写✍🏻),你可能会需要使用到谷歌翻译;后续大家可以自行学习如何优化提示词,最好限定在75个字符以内(提示词又称关键词);
提示词示例1

参阅:https://civitai.com/images/1384909?postId=355960&tags=5207
大模型:DreamShaper(类型:CHECKPOINT TRAINED);
额外调用的模型:lora:TotemPunkAI(类型:LORA);lora:AbsinthePunkAI(类型:LORA);
Prompt(提示词)
a painting, a psychedelic portrait of a stunning north american indian, face tattoos, in a sioux dress, (elaborate epic headdress), front page of art station, video game characters designs, vibrantly colored, tan skin, orange flowing hair, header, AbsinthePunk setting (masterpiece:1.2) (best quality) (detailed) (intricate) <lora:TotemPunkAI:0.5> <lora:AbsinthePunkAI:1>Negative prompt(负面提示词)
nsfw, BadDream, UnrealisticDream-1, (nude) (photo photography photograph) (cartoon) (saturated) (grain) (deformed) (poorly drawn) (lowres) (lowpoly) (CG) (3d) (blurry) (out-of-focus) (depth_of_field) (duplicate) (watermark) (label) (signature) (text) (cropped) oversaturated, high contrast其中,lora:TotemPunkAI / lora:AbsinthePunkAI需要自行下载并放置在 models/Lora 文件夹下,如下下载?请参阅本文 下载模型 部分;
提示词示例2

参阅:https://civitai.com/images/1356361?postId=349775&tags=5207
大模型:Arthemy Comics(类型:CHECKPOINT MERGE);
额外调用的模型:lora:add_detail;
Propt(提示词)
((masterpiece:1.3,concept art,best quality,detailed)),snake oil,award winning illustration,<lora:add_detail:1>Negative prompt(负面提示词)
anime,toy,toys,easynegative,worst quality,text,watermark,signature,child提示词示例3(NSFW向)
参阅:https://civitai.com/images/1368179?postId=352342&tags=5193;
大模型:majicMIX realistic 麦橘写实(类型:CHECKPOINT MERGE);
额外调用的模型:majicMIX realistic 麦橘写实;
Prompt(提示词)
(oil painting on canvas:1.5), (NSFW:1.2), 1girl, feature, pureerosface_v1, Ambilight, slender waist, (Lying:1.2), (blue tattoo, Paint poured on the body:1.3), fingernails, (splash, brushwork:1.5), background,double exposure, fussion of fluid abstract art,(original illustration composition),( fusion of limited color, maximalism artstyle, geometric artstyle)Negative prompt(负面提示词)
(oil painting on canvas:1.5), (NSFW:1.2), 1girl, feature, pureerosface_v1, Ambilight, slender waist, (Lying:1.2), (blue tattoo, Paint poured on the body:1.3), fingernails, (splash, brushwork:1.5), background,double exposure, fussion of fluid abstract art,(original illustration composition),( fusion of limited color, maximalism artstyle, geometric artstyle)提示词优化

从照片提取提示词:image → prompt https://imagetoprompt.com/ (根据所提供的照片写提示词/也可称之为提示词反推,反向推理)
更多提示词可参阅C站:https://civitai.com/images (看看别人怎么写的)
更多提示词参考内容可查看本文后文 学习资料 部分;
Extras 图片高清化(特技2)
先这样(必须)
下载:RealESRGAN_x4plus.pth
下载:RealESRGAN_x4plus_anime_6B.pth
将下载好的 RealESRGAN_x4plus.pth/RealESRGAN_x4plus_anime_6B.pth 文件移至 stable-diffusion-webui/models/RealESRGAN 文件夹下;
安装证书:/Applications/Python 3.10 -> 双击 Install Certificates.command 文件;终端提示进程结束则表示安装成功;(本版本要求环境为 Python 3.10,如未来更新则以未来要求版本为准);
再那样(你想高清化哪里的图片)
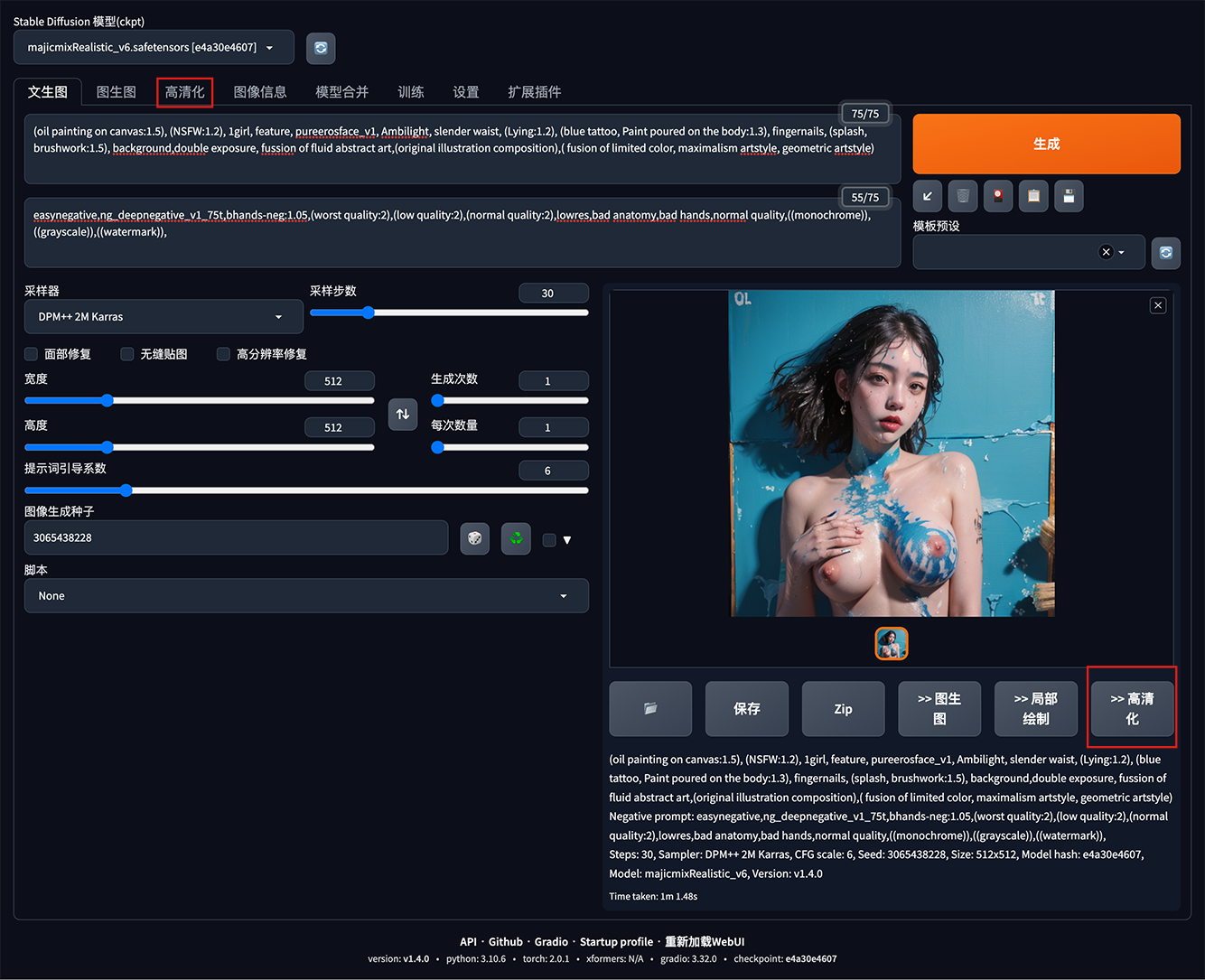
高清化效果参阅 -> 请确保已加入春潮频道;其中截图中的提示词可参阅(NSFW!);
高清化刚刚由 【文生图】 生成的图片:如果你刚刚使用文本生成图片/TEXT2IMG -> 觉得这张图挺满意的,但尺寸太小了!则可点击这张图 右下角的高清化/Extras 按钮!
从【本地选取图片】:当然,如果你看到一张不错的网图,但尺寸太小了!则可直接点击文生图/TEXT2IMG 右边第三个 -> 高清化/Extras,直接从本地选取图片;
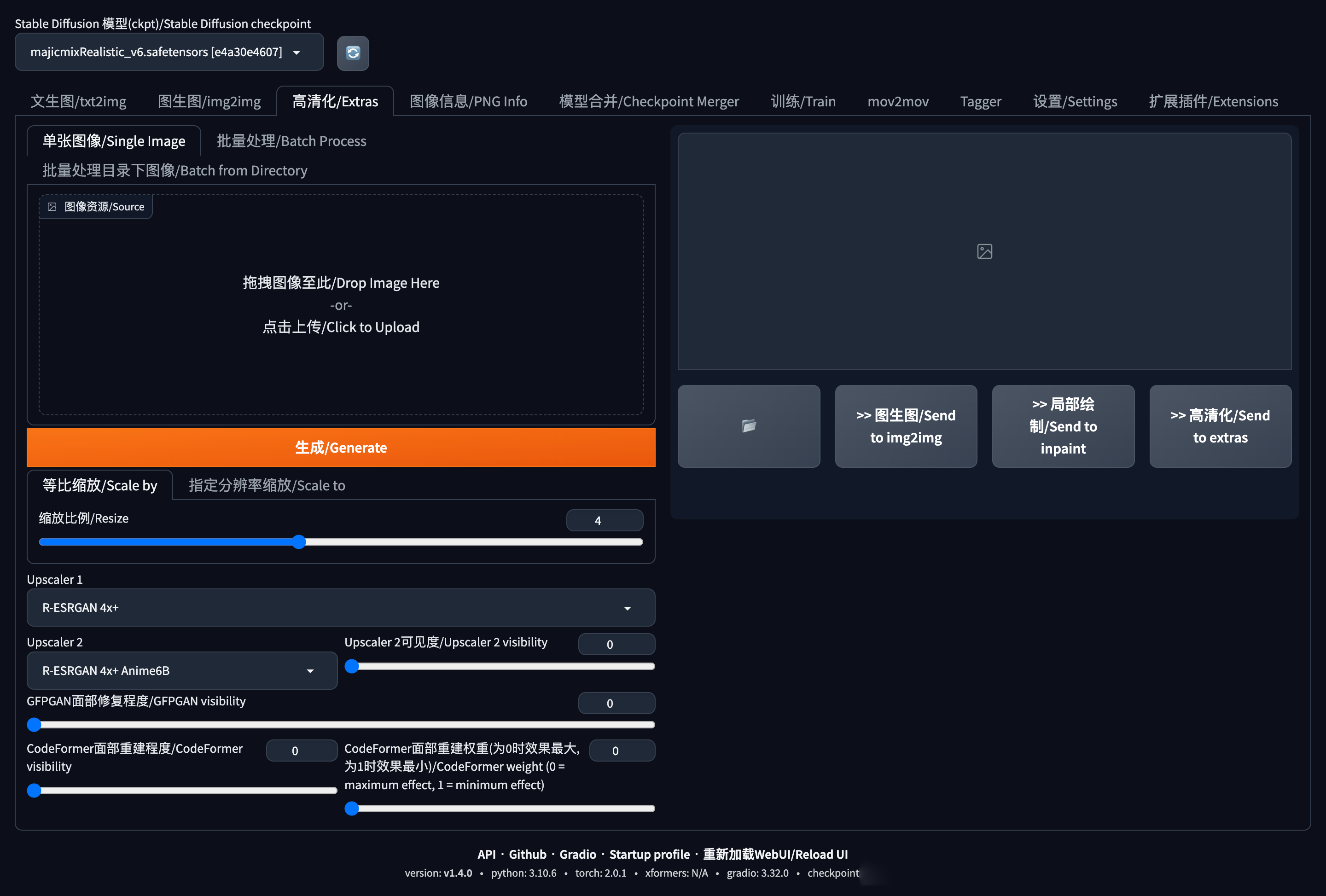
等比缩放:按需填写参数,比如2倍;(如果你的机子运力不行,这个参数尽量小,不然会花费很长时间;)
upscaler 是什么及其如何选择
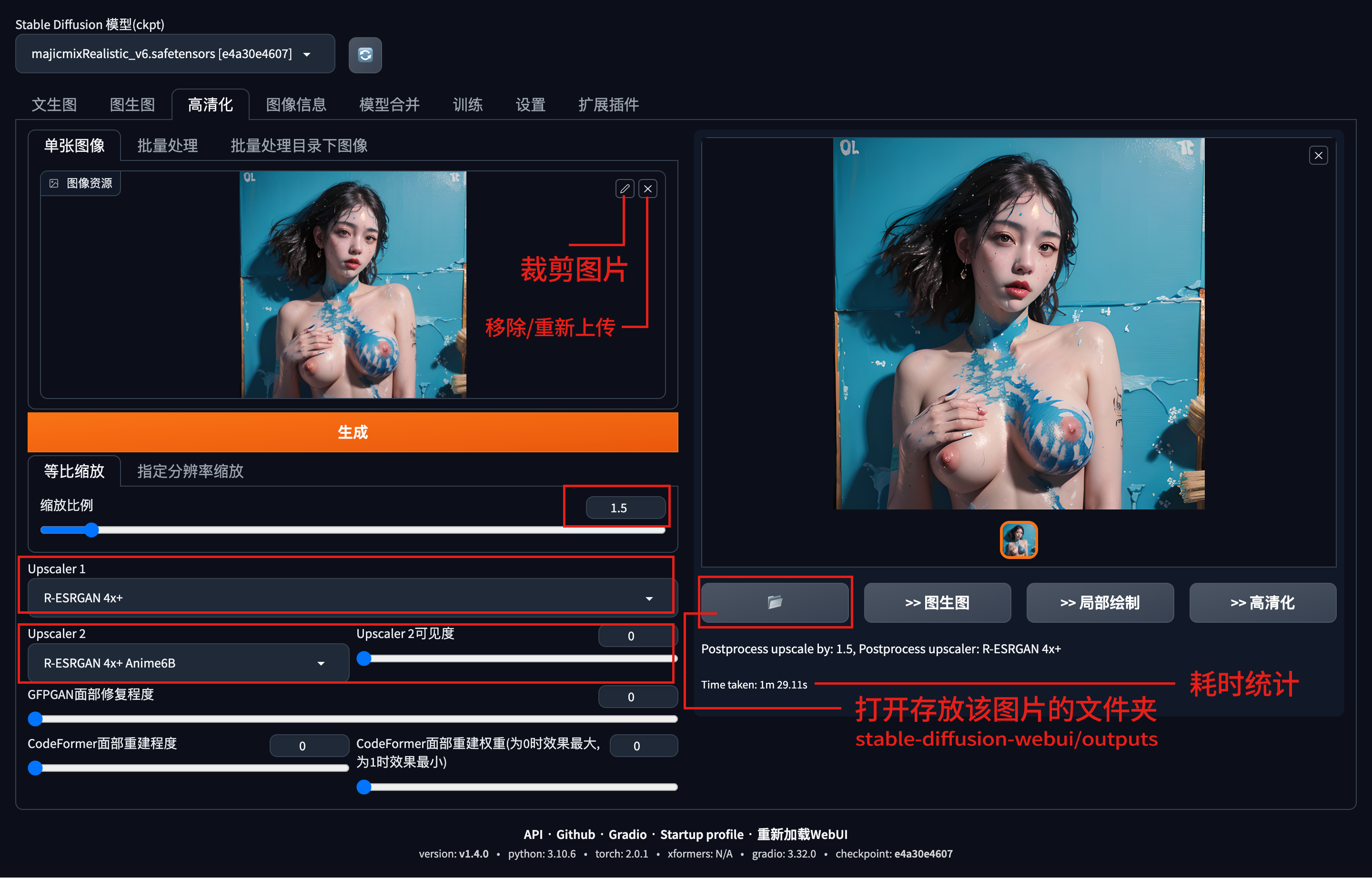
upscaler1 选择 R-ESRGAN 4x+;upscaler2 选择 R-ESRGAN 4x+ Anime6B;(仅做操作指引,后期你想怎么选怎么选);
Upscaler 1 & Upscaler 2 :放大/提升图片的时候可以只用一种放大器(不只是放大/也更清晰),也可以混合使用二种放大器。
Upscaler,即图像高清修复算法处理的技术。 与传统的Upscaler 不同,AI Upscaler 是一种模型学习技术,通过大量数据训练神经网络模型来恢复原始图像,并能够填补缺失信息。
目前 Stable Diffusion WebUI的放大器包含 LDSR、BSRGAN、ESRGAN_4x、R-ESRGAN-General-4xV3、R-ESRGAN-General-WDN-4xV3、R-ESRGAN-AnimeVideo、R-ESRGAN-4x+、R-ESRGAN-4x+-Anime6B、ScuNET-GAN、ScuNET-PSNR、SwinIR_4x;
Real-ESRGAN:Reddit 网友在 The DEFINITIVE Comparison to Upscalers 一文对各类型的放大器进行了比较:
And I'll summarize the rest:
| Upscaler | Photos | Paintings | Anime/Animation |
|---|---|---|---|
| LDSR | Much slower than anything else, but very good for photos | Too much random noise | Better, but still noisy |
| BSRGAN | Good, subtly sharp without going too far | Okay, but maybe a bit too smooth | Good, but R-ESRGAN is better |
| ESRGAN_4x | SUPER sharp, good here, but might be a tad too unrealistic | Too grainy, but might be good for a textured paint look | Terrible, worse than non-AI methods |
| R-ESRGAN-General-4xV3 | Okay, like BSRGAN, but a bit too much blur | Ditto | Much better here, but not as good as R-ESRGAN-Anime |
| R-ESRGAN-General-WDN-4xV3 | Closer to BSRGAN | Very good, texture and definition without being overbearing | Also good, also not as good as R-ESRGAN-Anime |
| R-ESRGAN-AnimeVideo | Tends to "unphoto" a subject | Ditto | 2nd best for anime, but Anime6B is better |
| R-ESRGAN-4x+ | Basically BSRGAN | Slightly more texture than BSRGAN | Basically BSRGAN |
| R-ESRGAN-4x+-Anime6B | Straight-up anime dog | Also anime | The best for anime |
| ScuNET-GAN | Too blurry | Too blurry | Average |
| ScuNET-PSNR | Too blurry | Too blurry | Hot garbage |
| SwinIR_4x | Yuck, I see tile lines! | Good, but not as textured as General-WDN | Hot garbage |
TL;DR 长话短说
| Picture type/图片类型 | Recommendations 推荐使用相应放大技术 |
|---|---|
| Photos/真人照片 | LDSR (but it's slow), or ESRGAN_4x if you want to super-sharp detail and/or speed, or BSRGAN for subtly |
| Paintings/绘画 | ESRGAN_4x for high paint texture and detail, General-WDN for a better overall look |
| Anime/二次元 | Anime6B, also good for turning something into anime |
参阅:How to use AI upscaler to improve image detail
其他放大器下载:To install a new upscaler in AUTOMATIC1111 GUI, download a model from the upscaler model database and put it in the folder;
stable-diffusion-webui/models/ESRGANRestart the GUI. Your upscaler should now be available for selection. Below is what you should see after installing the Universal Upscaler V2.
FAQ
如果选择放大器后,点击生成,但生成过程中提示错误❌(如.pth不存在...);则可能相应放大器未存放在 models 下的相应的文件夹下;谷歌搜索该 放大器名称+upscales 即可找到相应资源,并放置到相应文件夹下即可;
IMG2IMG 图生图(特技3)
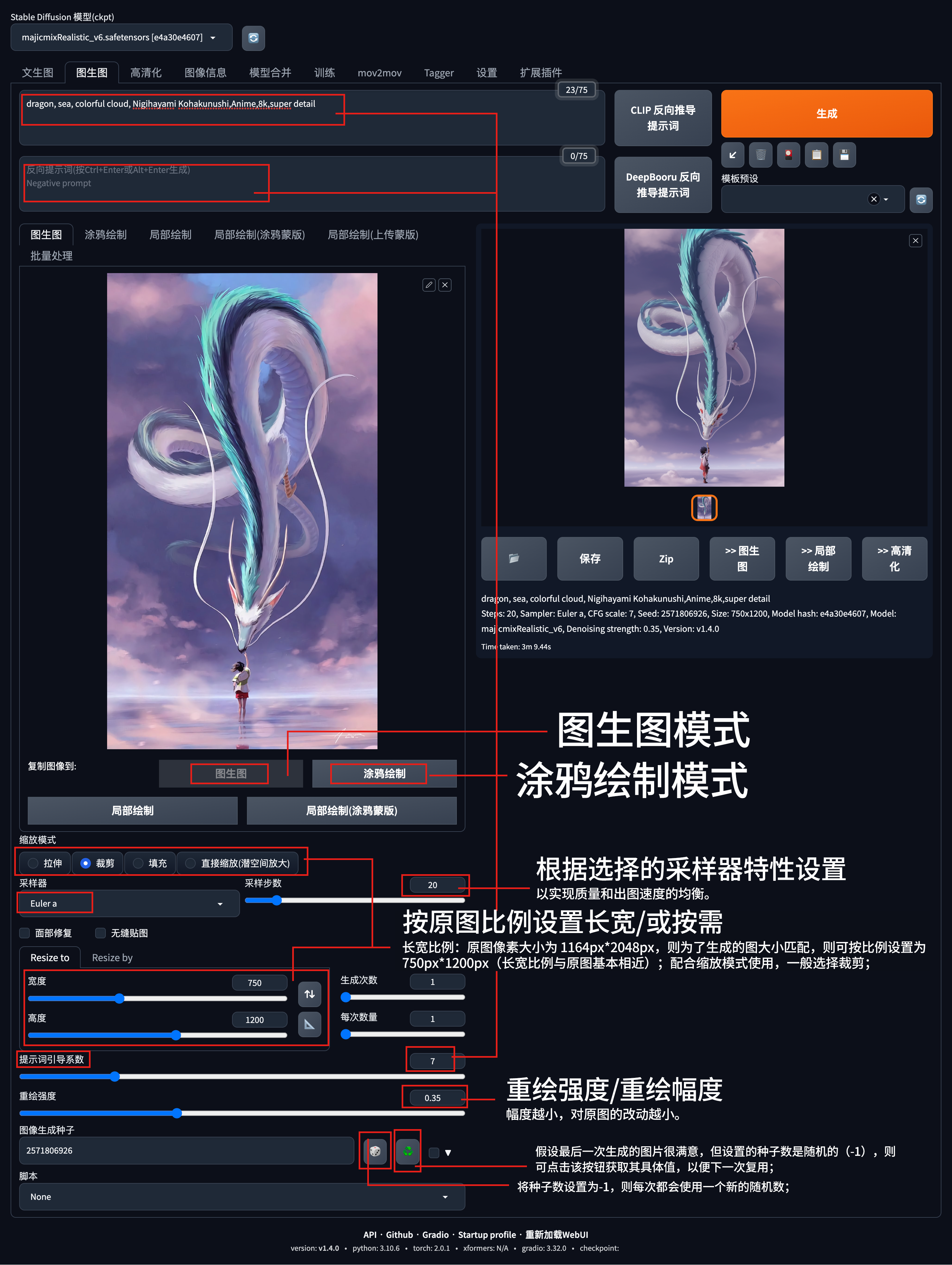
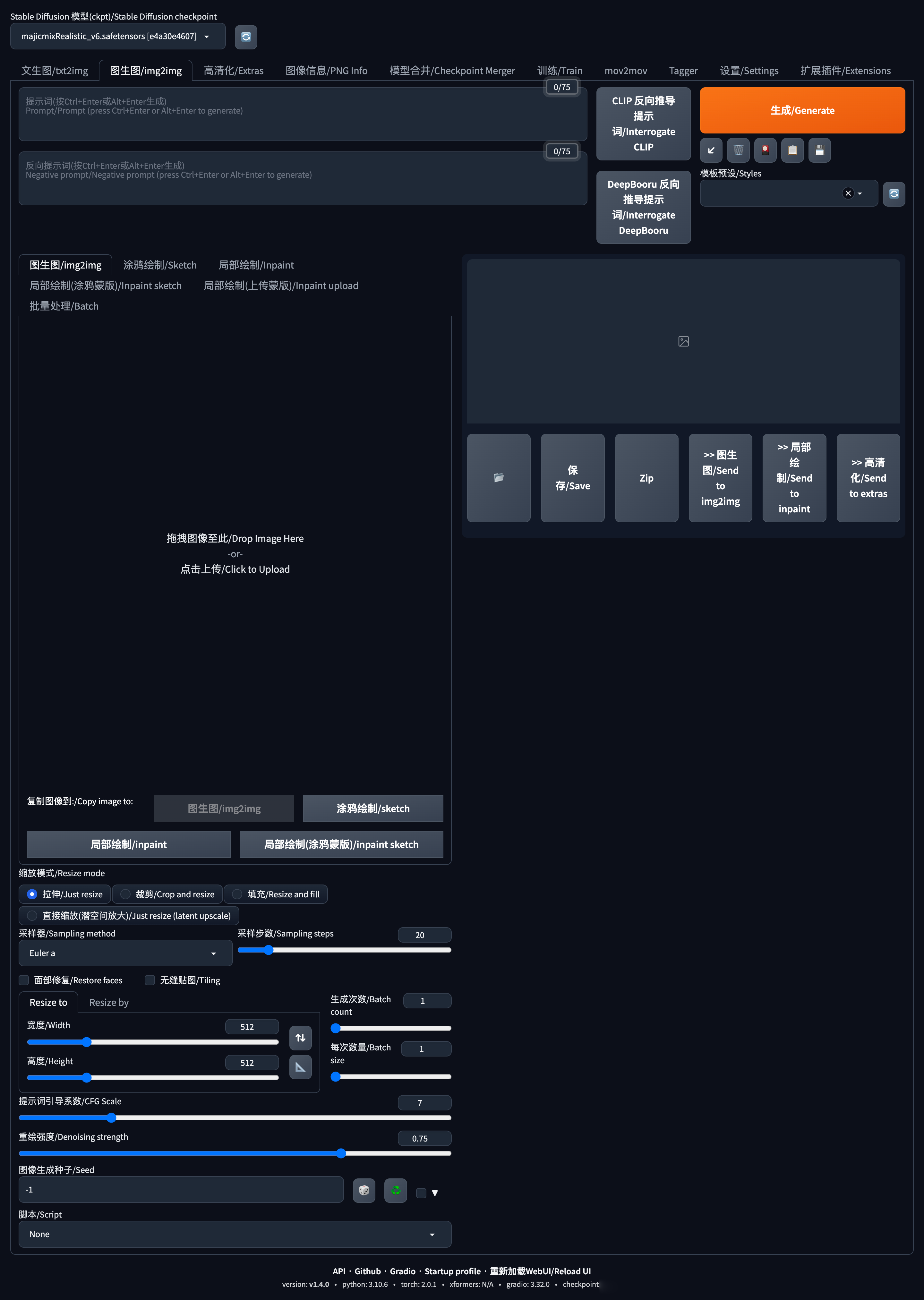
图生图效果参阅

重要知识:
重绘幅度(Denoising strength):即重新绘制的幅度,取值范围是0-1,默认设置0.75。可以简单理解为百分比,比例越小,对图片的影响越小,原图保留的细节就越多;反之,则天马行空,原图将完全重绘;
图生图/img2img:本章节;
涂鸦绘制/Sketch:你在画板画个很艹的草图,然后模型根据你的草图生成图片,实现神笔马良的效果,当然,主要还得看你的画技;
局部绘制/Inpaint:在原图上使用画笔工具圈出想要进行重绘的部分/或不想重绘的部分,再对这些部分生成图片;
局部绘制(涂鸦蒙版)/Inpaint sketch:未尝试;
反向推导提示词(CLIP-DeepBooru/DeepBooru)
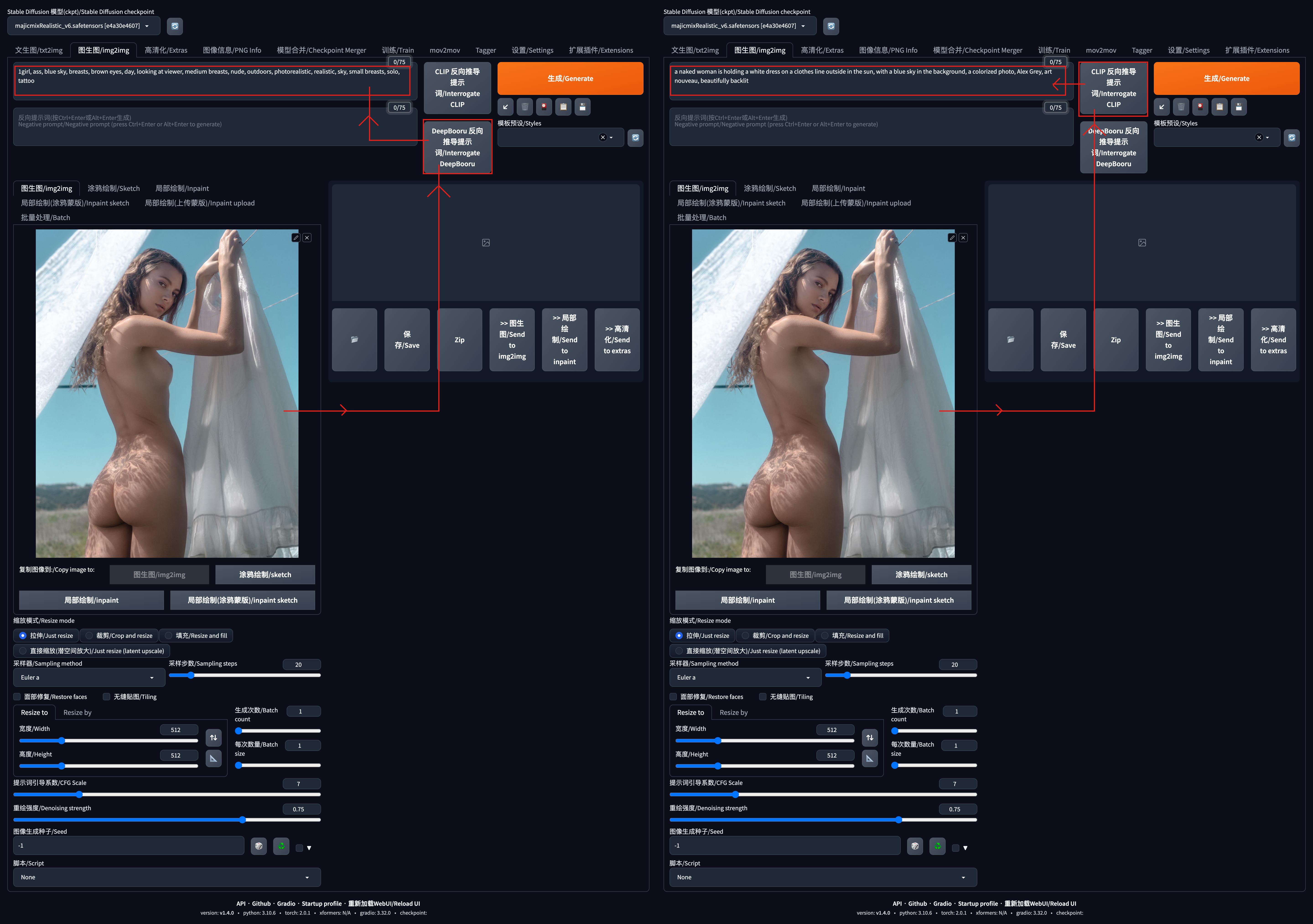
CLIP 反向推导提示词/Interrogate CLIP:上传图片后,点击 CLIP 反向推导提示词 Prompt,得到完整的英文句子;(算力差的计算机可能会耗时很久才会有结果);结果如下:
a naked woman is holding a white dress on a clothes line outside in the sun, with a blue sky in the background, a colorized photo, Alex Grey, art nouveau, beautifully backlitDeepBooru 反向推导提示词/Interrogate DeepBooru:同上,主要推到提示词Prompt/标签TAG,而不是完整的英文句子;会快很多;结果如下:
1girl, ass, blue sky, breasts, brown eyes, day, looking at viewer, medium breasts, nude, outdoors, photorealistic, realistic, sky, small breasts, solo, tattoo
推荐使用:从照片提取提示词:image → prompt https://imagetoprompt.com/ (根据所提供的照片写提示词/也可称之为提示词反推,反向推理);
其他参数:同TXT2IMG文生图,在此不再赘述;
不得不说的是,学转手绘的同学有福了! AI换脸 ... 对于学过 Photoshop 的小伙伴,IMG2IMG 图生图操作会变得非常简单。img2img/Sketch/Inpaint/Inpaint Sketch/Inpaint upload/Batch... 蒙版/画笔工具...
学习资料(术语/进阶指南)
提示词(Prompt)/负面提示词(Negative prompt)
Ultra-realistic 8k CG,masterpiece,best quality,(photorealistic:1.4),absurdres,HDR,RAW photo,(film grain:1.1),Bokeh,((Depth of field)),raytracing,detailed shadows,dim light,1 girl,full body,((looking at viewer:1.2)),(suspension:1.5),(spread legs:1.2),(shibari:1.4),sexy,(rope:1.3),bound hands,(arms behind back:1.2),(naughty_face:1.3),shaking,struggling,( half naked :1.4),small clothes,(single ponytail:1.3),(blushing face:1.2),((nsfw:1.4)),
(nude:1.2),(dim-lit room :1.2),wooden interior,metal chains,(ropeburns on wrists:1.3),( bra showing:1.3),curvy body,hanging planters,minimal furnishings,<lora:deliberate_v2:0.4>,(from above:1.2)第一个框框是提示词 (Prompt) 告诉AI要生成哪些东西;第二个框框是负向提示词 (Negative prompt) 告诉AI不要生成哪些东西。提示词(关键词)越靠前,生成时越先考虑;可参阅常用的关键词类别;
1.越前面的词,SD越会优先考虑,所以重要的词放前面;
2.同类词语放在一起,不要放重复词,比如描写背景的就都写一起;
3.只写必要的关键词。
(photorealistic:1.4):关键词:权重的组合;
<lora:deliberate_v2:0.4>:模型:权重的组合;lora:deliberate_v2 即调用 models/Lora 文件夹下的 deliberate_v2 模型;
提示词调用LoRA模型示例:我们把 deliberate_v2.safetensors 放在 models/Lora 文件夹下;
提示词优化
更多提示词可参阅C站:https://civitai.com/images
从照片提取提示词:image → prompt https://imagetoprompt.com/ (根据所提供的照片写提示词)
正面提示词参考
环境描写
stunning environment / 令人惊讶的环境 / 让AI根据其他关键字做出充满创造力的风景
aerial view / 空中鸟瞰 / 鸟瞰远景镜头
landscape / 风景画 / 通常是山野风情画背景
aerial photography / 鸟瞰绘图 / 类似aerial view
massive scale / 宏伟构图 / 建筑物的密度与高度有可能被夸大
street level view / 街头景色 / 从路面上平视的街景
lush vegetation / 植物茂盛 / 植物茂盛的景色
idyllic / 瑞士乡间 / 理想退休人士居住的天堂般宁静乡间
overhead shot / 正上方鸟瞰 / 正上方或斜上方视角
Matte painting / 接景 / 将数种风景地貌拼接在一起
blurry background / 模糊背景 / 将背景模糊创造聚焦效果细节描写
wallpaper / 壁纸
poster / 挂报
sharp focus / 鋭焦
hyperrealism / 超写实主义
insanely detailed / 密密麻麻的细节
lush detail / LUSH化妆品美颜
filigree / 植物纹精工金饰
intricate / 丝线精工金饰
crystalline / 水晶首饰
perfectionism / 完美主义
max detail / 最大化细节
spirals / 漩涡纹
tendrils / 植物首饰
ornate / 复杂装饰纹
angelic / 天使般
decorations / 盛装
embellishments / 礼服镶嵌碎花
hard edge / 棱角分明
breathtaking / 令人屏息
embroidery / 刺綉
tiara / 王冠其他正面提示词参阅:
Stable Diffusion提示词-- 细节;
Stable Diffusion提示词-- 环境;
Stable Diffusion提示词-- 光影;
Stable Diffusion提示词-- 姿势;
负面提示词参考
Easy Negative,worst quality,low quality,normal quality,lowers,monochrome,grayscales,skin spots,acnes,skin blemishes,age spot,6 more fingers on one hand,deformity,bad legs,error legs,bad feet,malformed limbs,extra limbs,ugly,poorly drawn hands,poorly drawn feet.poorly drawn face,text,mutilated,extra fingers,mutated hands,mutation,bad anatomy,cloned face,disfigured,fused fingersEasy Negative / 简单负面
worst quality / 最差品质
low quality / 低品质
normal quality / 正常品质
lowers / 降低
monochrome / 单色
grayscales / 灰阶
skin spots / 皮肤斑点
acnes / 脓疮,痘疤
skin blemishes / 皮肤瑕疵
age spot / 老人斑
6 more fingers on one hand / 多手指
deformity / 畸形
bad legs / 畸形腿
error legs / 错腿
bad feet / 脚型不正
malformed limbs / 畸形四肢
extra limbs / 多余肢体
ugly / 丑
poorly drawn hands / 差劲画技的手
poorly drawn feet / 差劲画技的足
poorly drawn face / 差劲画技的脸
text / 文字
mutilated / 伤口
extra fingers / 多余手指
mutated hands / 突变手掌
mutation / 突变
bad anatomy / 差劲生理结构
cloned face / 重复面孔
disfigured / 变形
fused fingers / 手指融合采样器介绍(sampler)
AUTOMATIC1111中的采样器(Sampling method)有很多,包括Euler a、Heun和DDIM等。Stable Diffusion使用采样方法去除图像噪声,生成随机图像并重复几次这个过程得到干净的图像。去噪的方法有很多种。通常需要在速度和准确性之间做出权衡。
进一步了解:https://zhuanlan.zhihu.com/p/621083328 在此不再赘述;
文生图(TXT2IMG)
用户界面术语
高度/宽度:如果感觉生成的图片不完全则可适当增加宽度或高度(譬如腿部只露出到膝盖..);
提示词引导系数(CFG scale):图像与提示符的一致程度——越低的值产生越有创意的结果;
图像生成种子(seed):种子数,只要种子数一样,参数一致、模型一致 就能重新生成一样的图像;也就说,在其他条件不变的情况下,修改下种子数可以得到更多意想不到的变体(当然,画面主体不变,但有更多演化);种子数为-1时,则代表随机;
随机数差异种子(Variation seed)/差异程度(Variation strength):保持其他条件不变的情况下,调整随机数差异种子或差异强度,可在当前已生成图片的基础上微调;
生成次数(Batch count)/每次生成数量(Batch size):决定生成的图片数量。如果显存足够,则可以增加 Batch Size;否则,只能增加 Batch Count,得到的图片数量是两者之积(对于显存较小的情况,建议只修改 Batch Count)。
采样步数/Sampling steps**:不同采样器有不同的采样步数推荐;(关于更多采样步数的说明,请参阅后文 学习资料 部分)
1.如果只是想得到一些较为简单的结果,选用欧拉(Eular)或者Heun,并可适当减少Heun的步骤数以减少时间;
2.对于侧重于速度、融合、新颖且质量不错的结果,建议选择:
DPM++ 2M Karras, Step Range:20-30
UniPc, Step Range:20-30
3.期望得到高质量的图像,且不关心图像是否收敛:
DPM ++ SDE Karras, Step Range:8-12
DDIM, Step Range:10-15
4.如果期望得到稳定、可重现的图像,避免采用任何祖先采样器;
Via Stable Diffusion-采样器篇;Stable Diffusion 小知识:采样方法(Sampler method)和采样迭代步骤(steps)(不同采样器,不同步数下的差别,有图示;);
常用的关键词类别
(1) 主体 subject
(2) 媒介 medium
(3) 风格 style
(4) 画家 artist
(5) website
(6) 分辨率 resolution
(7) 额外细节 additional details
(8) 色调 color
(9) 光影 lighting图生图(IMG2IMG)
用户界面术语
CLIP 反向推导提示词/Interrogate CLIP:上传图片后,点击 CLIP 反向推导提示词 Prompt,得到完整的英文句子;(算力差的计算机可能会耗时很久才会有结果)!但结果相较于 Interrogate DeepBooru反向推导提示词 更胜一筹!这个甲方需求更明确!完整的句子!而不是几个英文单词/TAG!GET?结果如下:
a naked woman is holding a white dress on a clothes line outside in the sun, with a blue sky in the background, a colorized photo, Alex Grey, art nouveau, beautifully backlitDeepBooru 反向推导提示词/Interrogate DeepBooru:同上,主要推到提示词Prompt/标签TAG,而不是完整的英文句子;会快很多;结果如下:
1girl, ass, blue sky, breasts, brown eyes, day, looking at viewer, medium breasts, nude, outdoors, photorealistic, realistic, sky, small breasts, solo, tattoo
推荐使用:从照片提取提示词:image → prompt https://imagetoprompt.com/ (根据所提供的照片写提示词/也可称之为提示词反推,反向推理);
Extensions(扩展)及扩展推荐
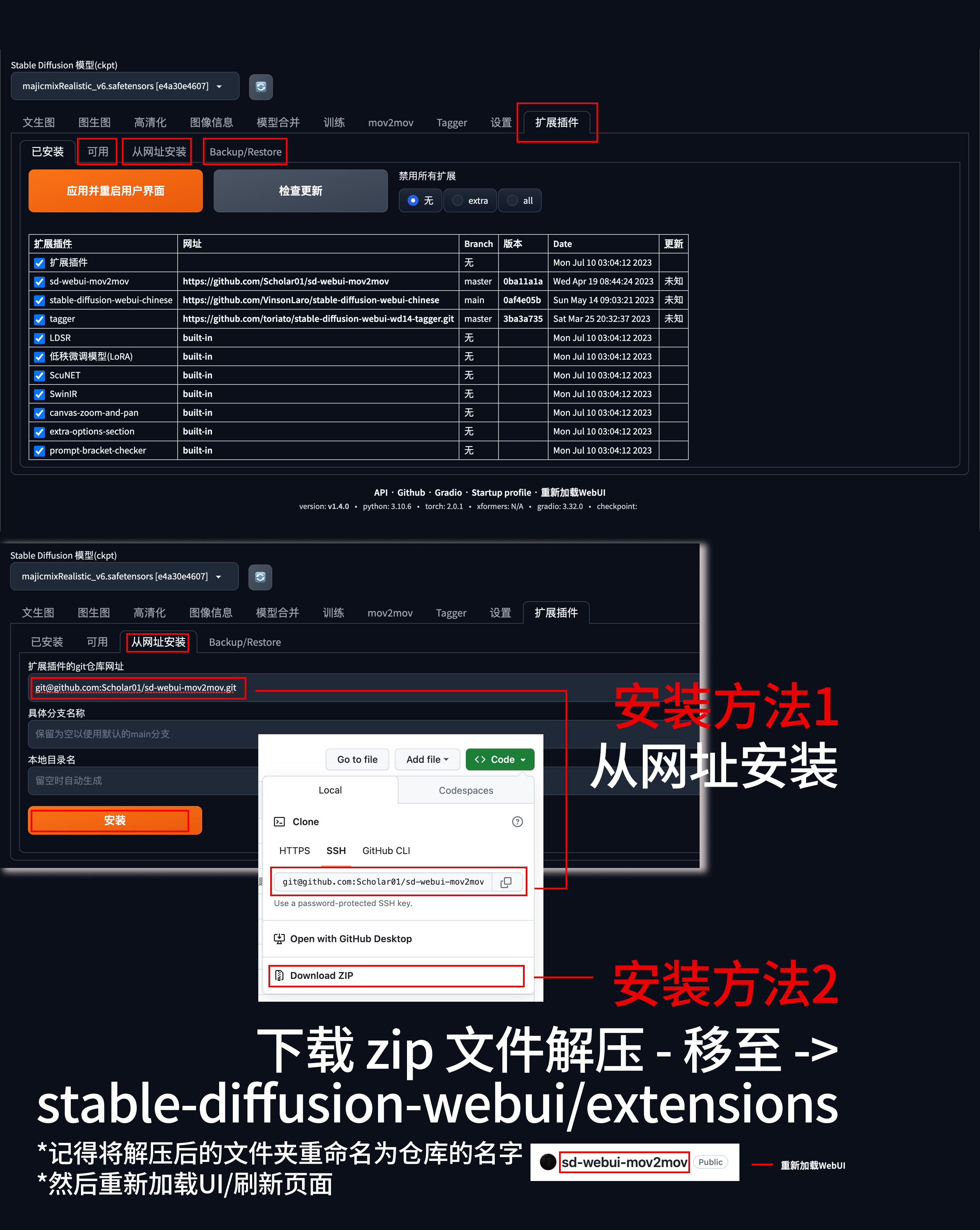
“stable-diffusion-webui 为了只保证核心功能并便于管理,将非核心功能解耦并转为扩展和脚本形式提供;” Via Stable Diffusion高级教程;除了中文扩展之外,还有很多好玩的扩展,功能性极强;如 mov2mov+Controlnet(让AI老婆动起来)、Tagger(从图片反推提示词!)...;脸部/手部完美修复工具ADetailer...(很好用!);
官方参阅:https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Extensions (里面有超过扩展推荐)...
基本上,大家可以玩一阵了;
参阅1:stable-diffusion-webui-WIKI;(stable-diffusion-webui 自己的维基百科,包含以下内容:)
Features
Textual Inversion
Negative prompt
Seed breaking changes
Dependencies
Xformers
Installation and run on NVidia GPUs
Install and run on AMD GPUs
Install and run on Apple Silicon
Command Line Arguments and Settings
Optimizations
Custom scripts
Developing custom scripts
Extensions
Developing extensions
Troubleshooting
Contributing
Online Services
Localization
Custom Filename Name and Subdirectory
Change model folder location e.g. external disk
API
Tests
Guides and Tutorials
参阅2:StableDiffusionBook;(中文!类似于SD的Cookbook;“StableDiffusionBook 致力于信息公开和社区连结,秉持开放,共建的原则进行社区文档建设。任何人都可以参与到此文档的编写工作。”)新人必看!
参阅3:手把手教你用Stable Diffusion写好提示词;
提示词优化器开源4:https://github.com/Moonvy/OpenPromptStudio;
AI Generated Prompt:image → prompt Go from image to stable diffusion prompt in 30s https://imagetoprompt.com/
AIGC 交流
https://www.reddit.com/r/midjourney/
https://www.reddit.com/r/StableDiffusion/
Faq
人脸/手生成不完美如何解决?
那就用用 adetailer 扩展吧;
提示内存不足
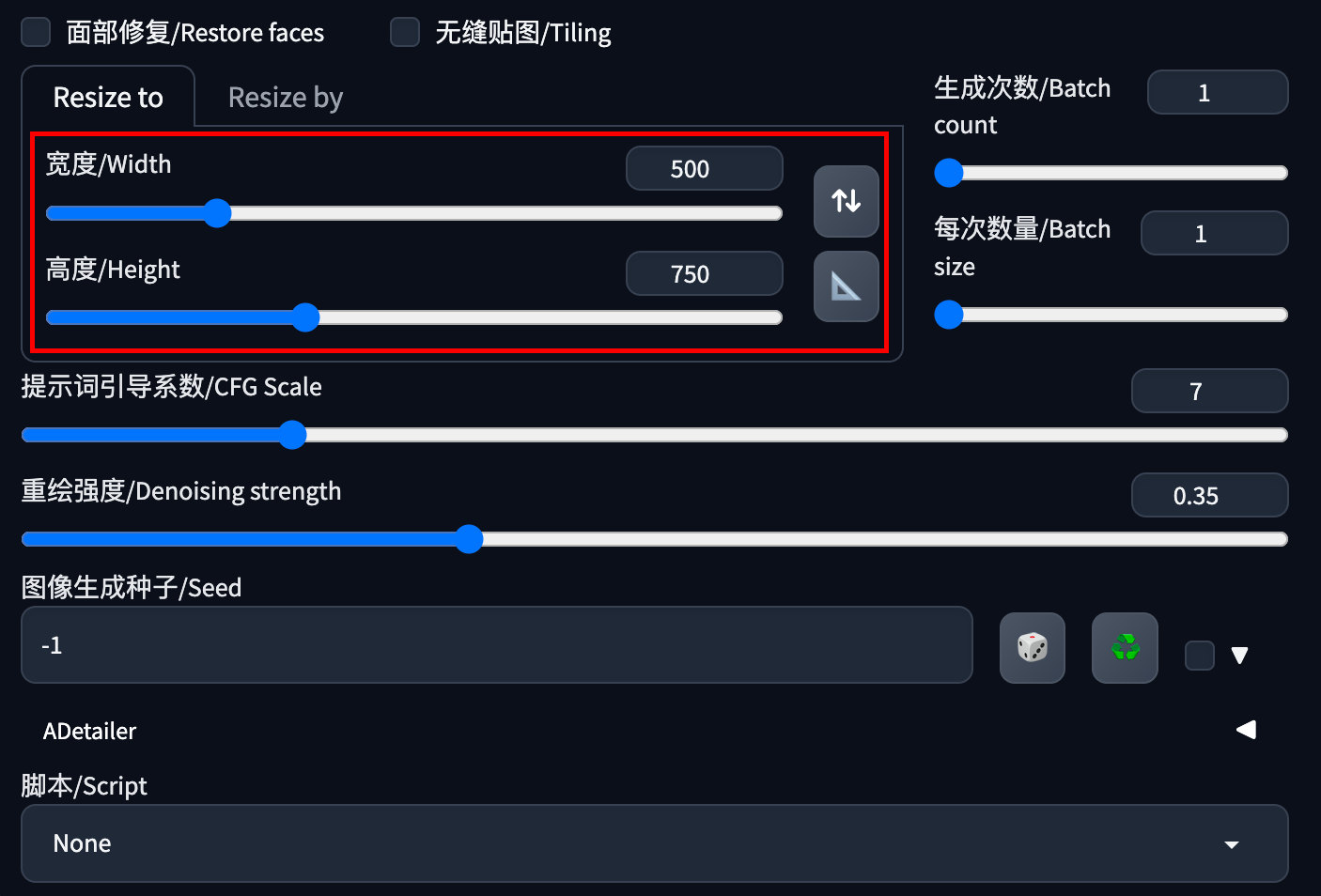
1.调整(调小!)待生成图片的宽(Width)/高(Height);
2.扩大计算机内存条;
3.关闭或调整一些可能导致内存消耗过大的参数;
后记
可以多花时间了解提示词优化...
各种模型/采样器的差别...
持续更新中...
版权属于:毒奶
联系我们:https://limbopro.com/6.html
毒奶搜索:https://limbopro.com/search.html
番号搜索:https://limbopro.com/btsearch.html
机场推荐:https://limbopro.com/865.html IEPL专线/100Gb/¥15/月起(最高享8折优惠)
毒奶导航:https://limbopro.com/daohang/index.html本文链接:https://limbopro.com/archives/install_and_quickstart_Stable_Diffusion.html · 镜像:https://limbopro.github.io/archives/install_and_quickstart_Stable_Diffusion.html
本文采用 CC BY-NC-SA 4.0 许可协议,转载或引用本文时请遵守许可协议,注明出处、不得用于商业用途!




